


Ένα νέο μοντέλο τεχνητής νοημοσύνης από τη Google, το Gemini 2.0 Flash, επαναστατεί στον τομέα της επεξεργασίας εικόνας, επιτρέποντας στους χρήστες να τροποποιούν ή να δημιουργούν εικόνες απλά με εντολές μέσω συνομιλιών με chatbot.
Τα αποτελέσματα δεν είναι τέλεια, αλλά είναι πολύ πιθανό ότι στο κοντινό μέλλον όλοι θα μπορούν να επεξεργάζονται εικόνες με αυτόν τον τρόπο.
Gemini 2.0 Flash: Επέκταση δυνατοτήτων δημιουργίας εικόνας
Την προηγούμενη Τετάρτη, η Google επέκτεινε την πρόσβαση στις δυνατότητες δημιουργίας εικόνας του Gemini 2.0 Flash, οι οποίες ήταν διαθέσιμες μόνο σε δοκιμαστές από τον Δεκέμβριο.
Αυτή η πολυτροπική τεχνολογία συνδυάζει τις δυνατότητες επεξεργασίας κειμένου και εικόνας σε ένα μόνο μοντέλο τεχνητής νοημοσύνης.
Τώρα είναι διαθέσιμη για όλους τους χρήστες του Google AI Studio, επιτρέποντας στους χρήστες να αλληλεπιδρούν με την τεχνητή νοημοσύνη και να τροποποιούν εικόνες απλά πληκτρολογώντας εντολές.

Βασικά χαρακτηριστικά και δυνατότητες
Το νέο μοντέλο Gemini 2.0 Flash έχει ήδη προκαλέσει αίσθηση, καθώς επιτρέπει την επεξεργασία εικόνας με φυσικό διάλογο. Οι χρήστες μπορούν να δώσουν εντολές στην τεχνητή νοημοσύνη για να προσθέσουν ή να αφαιρέσουν αντικείμενα, να τροποποιήσουν το φως, το background, ή ακόμη και να αλλάξουν γωνία και ζουμ στις εικόνες.
Παρόλο που τα αποτελέσματα δεν είναι πάντα τέλεια, η ικανότητα της τεχνητής νοημοσύνης να «κατανοεί» τις εντολές και να ανταποκρίνεται ανάλογα είναι εντυπωσιακή.
Ποια είναι τα όρια της νέας τεχνολογίας
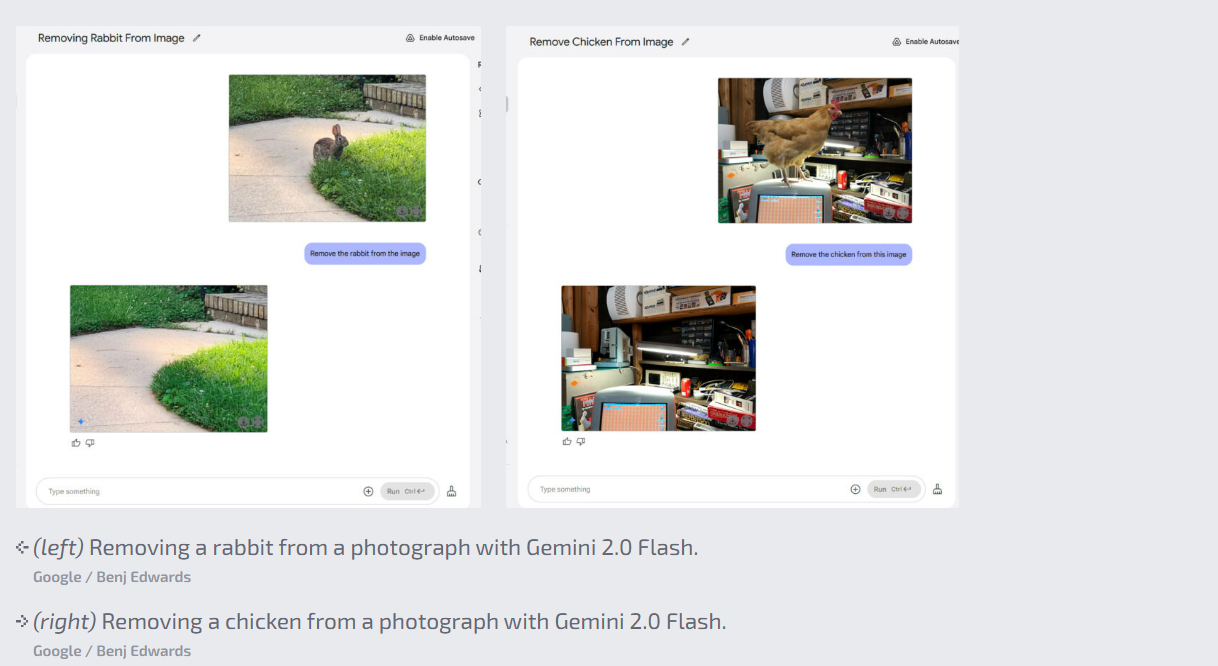
Η τεχνητή νοημοσύνη του Gemini 2.0 Flash, ενώ είναι αρκετά ισχυρή, δεν είναι τέλεια. Για παράδειγμα, αφαιρώντας ένα κουνέλι από μια εικόνα σε έναν χλοοτάπητα, η τεχνητή νοημοσύνη συμπλήρωσε το φόντο με την καλύτερη της εκτίμηση, χωρίς την ανάγκη χρήσης του γνωστού «clone brush» που χρησιμοποιούν οι χρήστες στο Photoshop.

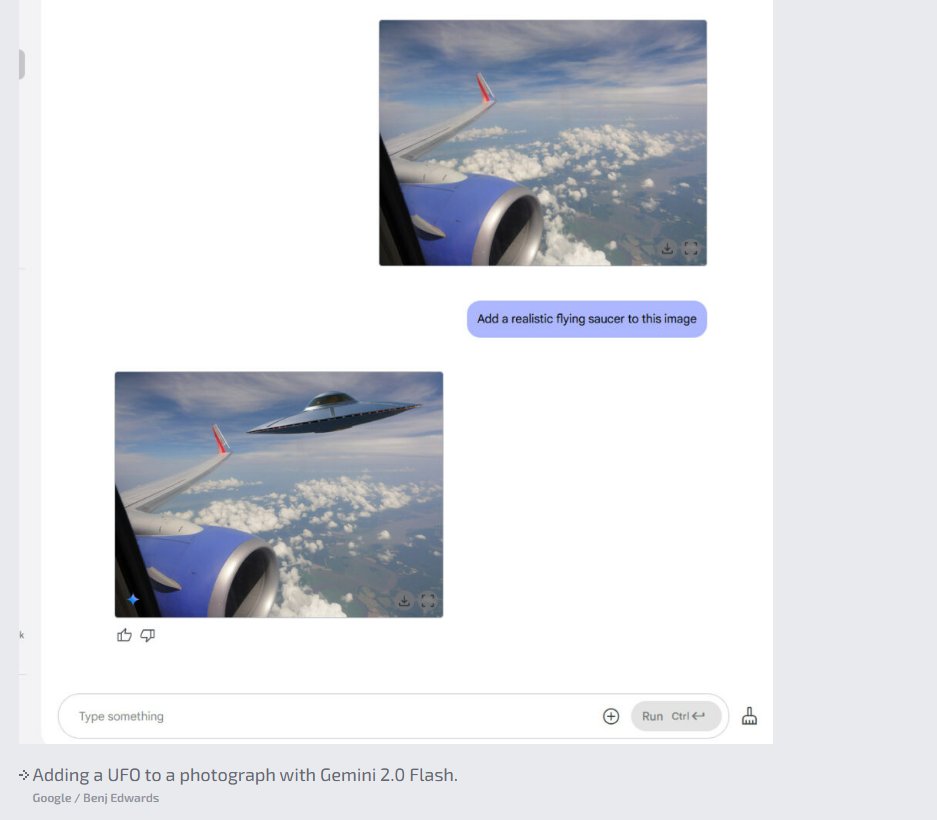
Ωστόσο, κάποια αποτελέσματα, όπως η προσθήκη ενός UFO ή ενός Μεγαλοπόδαρου, δεν ήταν ρεαλιστικά λόγω των περιορισμένων δεδομένων εκπαίδευσης του μοντέλου.

Το μέλλον της επεξεργασίας εικόνας με AI
Με τη νέα αυτή τεχνολογία, η Google δείχνει τη δυνατότητα για ένα νέο είδος επεξεργασίας εικόνας, που συνδυάζει τον φυσικό διάλογο με την επεξεργασία οπτικών μέσων. Αν και τα αποτελέσματα δεν είναι πάντα τέλεια, ανοίγεται μια νέα εποχή στην επεξεργασία εικόνας, με τη βοήθεια της τεχνητής νοημοσύνης.
Παρά τις αδυναμίες του Gemini 2.0 Flash μέχρι στιγμής, η εμφάνιση της αληθινής πολυτροπικής εξόδου εικόνας φαίνεται να είναι μια σημαντική στιγμή στην ιστορία της τεχνητής νοημοσύνης λόγω του τι υποδεικνύει για το μέλλον, αν η τεχνολογία συνεχίσει να βελτιώνεται.
Αν φανταστείτε έναν μελλοντικό κόσμο, ας πούμε 10 χρόνια από τώρα, όπου ένα επαρκώς πολύπλοκο μοντέλο τεχνητής νοημοσύνης μπορεί να δημιουργήσει οποιοδήποτε τύπο μέσου σε πραγματικό χρόνο – κείμενο, εικόνες, ήχο, βίντεο, 3D γραφικά, 3D εκτυπωμένα φυσικά αντικείμενα και διαδραστικές εμπειρίες – καταλαβαίνετε τι αλλαγές έρχονται.
Αναγνώριση της «πρώιμης» κατάστασης της πολυτροπικής εξόδου εικόνας
Επιστρέφοντας στην πραγματικότητα, η πολυτροπική έξοδος εικόνας είναι ακόμα στην «πρώιμη φάση» της και η Google το αναγνωρίζει αυτό. Θυμηθείτε ότι το Flash 2.0 έχει σχεδιαστεί ως ένα μικρότερο μοντέλο τεχνητής νοημοσύνης που είναι πιο γρήγορο και φθηνότερο στην εκτέλεση, οπότε δεν έχει αφομοιώσει όλη την έκταση του Διαδικτύου.
Όλες αυτές οι πληροφορίες απαιτούν μεγάλο χώρο σε όρους αριθμού παραμέτρων και όσο περισσότερες παράμετροι υπάρχουν, τόσο περισσότερη υπολογιστική ισχύ απαιτείται.
Αντίθετα, η Google εκπαίδευσε το Gemini 2.0 Flash παρέχοντας του μια επιλεγμένη βάση δεδομένων, η οποία πιθανότατα περιλάμβανε και συνθετικά δεδομένα. Ως αποτέλεσμα, το μοντέλο δεν «γνωρίζει» τα πάντα οπτικά για τον κόσμο και η Google λέει ότι τα δεδομένα εκπαίδευσης είναι «ευρεία και γενικά, όχι απόλυτα ή πλήρη».
Η ποιότητα της εξόδου εικόνας και η προοπτική βελτίωσης
Αυτό είναι απλά ένας τρόπος για να πούμε ότι η ποιότητα της εξόδου εικόνας δεν είναι τέλεια – ακόμα. Ωστόσο, υπάρχει άφθονος χώρος για βελτίωση στο μέλλον, προκειμένου να ενσωματωθεί περισσότερη «οπτική γνώση» καθώς οι τεχνικές εκπαίδευσης εξελίσσονται και η υπολογιστική ισχύς μειώνεται στο κόστος.
Εάν η διαδικασία γίνει παρόμοια με ό,τι έχουμε δει από γεννήτριες εικόνας βασισμένες σε διάχυση, όπως οι Stable Diffusion, Midjourney και Flux, η ποιότητα της πολυτροπικής εξόδου εικόνας μπορεί να βελτιωθεί γρήγορα μέσα σε σύντομο χρονικό διάστημα.
