

Στο Διεθνές Μαθηματικό Ολυμπιακό (IMO) 2024, ένας διαγωνιζόμενος πήγε τόσο καλά ώστε θα έπαιρνε Αργυρό Μετάλλιο – με μια μικρή λεπτομέρεια: δεν ήταν άνθρωπος, ήταν ένα σύστημα τεχνητής νοημοσύνης. Ήταν η πρώτη φορά στην ιστορία του θεσμού που ένα AI έφτασε σε επίδοση μετάλλου. Σε άρθρο που δημοσιεύτηκε στο Nature, οι ερευνητές περιγράφουν την τεχνολογία πίσω από αυτό το εντυπωσιακό κατόρθωμα.
AlphaProof
Το AI ονομάζεται AlphaProof, ένα προηγμένο πρόγραμμα της Google DeepMind που μαθαίνει να λύνει σύνθετα μαθηματικά προβλήματα. Η επίδοση στο IMO είναι μόνο η αρχή – αυτό που κάνει πραγματικά ξεχωριστό το AlphaProof είναι ότι μπορεί να βρίσκει και να διορθώνει λάθη, κάτι που τα περισσότερα LLM δεν μπορούν να εγγυηθούν. Ακόμη κι όταν λύνουν προβλήματα, μπορεί να κρύβονται σφάλματα στη συλλογιστική τους.
Το AlphaProof είναι διαφορετικό γιατί οι απαντήσεις του είναι πάντα 100% σωστές. Αυτό συμβαίνει επειδή χρησιμοποιεί το Lean, ένα αυστηρό περιβάλλον λογικής – αρχικά αναπτυγμένο από τη Microsoft Research – το οποίο λειτουργεί σαν «αυστηρός δάσκαλος» που ελέγχει κάθε βήμα. Ο υπολογιστής επαληθεύει μόνος του κάθε λογική κίνηση, οπότε τα συμπεράσματά του είναι αξιόπιστα.
Η τριπλή διαδικασία εκπαίδευσης
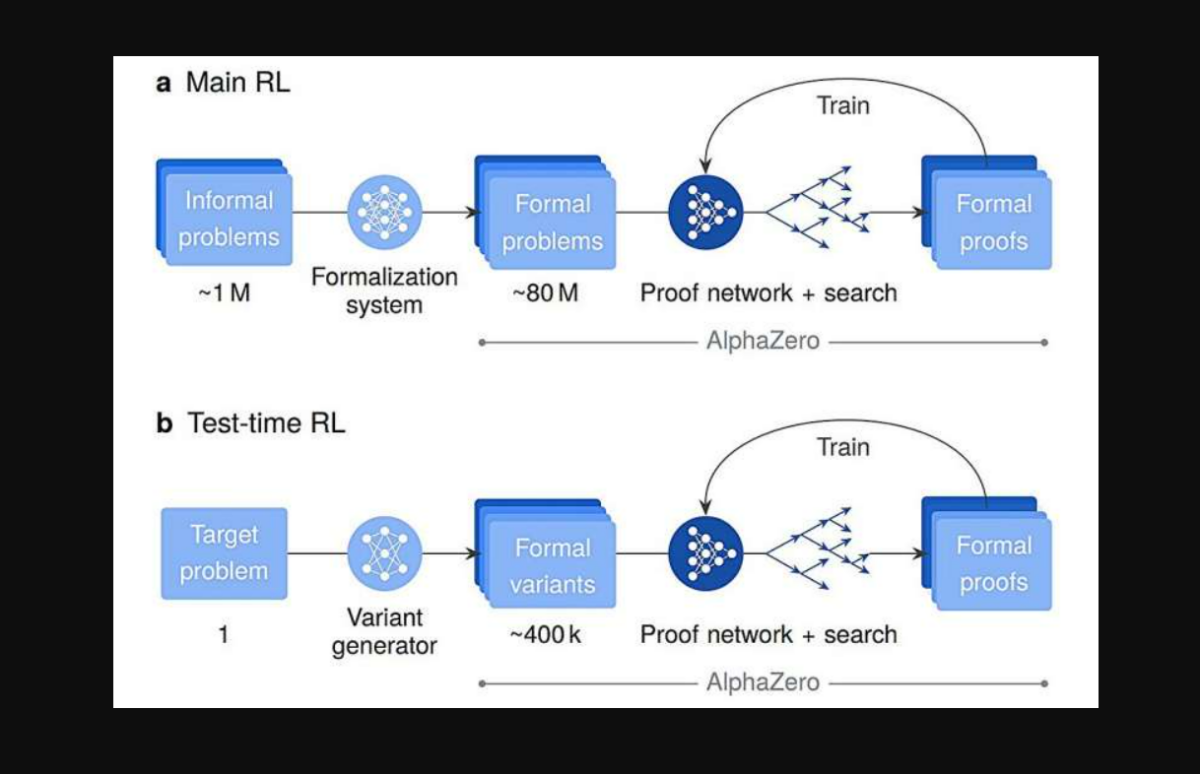
Για να εκπαιδευτεί ένα σύστημα που σκέφτεται σε ελίτ μαθηματικό επίπεδο, οι ερευνητές χρησιμοποίησαν τρεις φάσεις εκπαίδευσης. Αρχικά, το AlphaProof εκτέθηκε σε περίπου 300 δισεκατομμύρια tokens γενικού κώδικα και μαθηματικών κειμένων, ώστε να αποκτήσει ευρεία κατανόηση της λογικής, της μαθηματικής γλώσσας και της δομής προγραμμάτων. Στη συνέχεια, του δόθηκαν 300.000 αποδείξεις ειδικών, ήδη διατυπωμένες στο περιβάλλον Lean.
Η τελική φάση ήταν η πιο απαιτητική: το σύστημα έπρεπε να μάθει να λύνει προβλήματα μόνο του. Του ανατέθηκε ένας «μαραθώνιος εργασιών», 80 εκατομμύρια τυπικά μαθηματικά προβλήματα προς επίλυση. Με τη χρήση Reinforcement Learning (RL) – μάθηση μέσω δοκιμής και σφάλματος – το AlphaProof ανταμειβόταν κάθε φορά που παρήγαγε έγκυρη απόδειξη. Μέσα από αυτόν τον τεράστιο όγκο προκλήσεων, ανέπτυξε δικές του πολύπλοκες στρατηγικές συλλογισμού, ξεπερνώντας την απλή μίμηση ανθρώπινων παραδειγμάτων.
Για τα δυσκολότερα προβλήματα, το AlphaProof χρησιμοποιούσε μια τεχνική των ερευνητών, το Test-Time RL (TTRL), το οποίο δημιουργεί και λύνει εκατομμύρια απλοποιημένες εκδοχές του στόχου, μέχρι να εντοπίσει μια έγκυρη λύση.
Οι ερευνητές γράφουν:
«Το έργο μας δείχνει ότι η μάθηση μεγάλης κλίμακας από θεμελιωμένη εμπειρία δημιουργεί πράκτορες με πολύπλοκες μαθηματικές στρατηγικές συλλογισμού, ανοίγοντας τον δρόμο για ένα αξιόπιστο εργαλείο AI στην επίλυση περίπλοκων μαθηματικών προβλημάτων».
Το μέλλον της μαθηματικής έρευνας με το AlphaProof
Πέρα από το ότι λύνει φαινομενικά άλυτα προβλήματα, το AlphaProof θα μπορούσε να χρησιμοποιηθεί και από μαθηματικούς για να ελέγχει αποδείξεις, να εντοπίζει λάθη ή ακόμη και να βοηθά στη δημιουργία νέων θεωριών. Με τη σιγουριά της απόλυτης ακρίβειας και την ικανότητα να μαθαίνει νέες μεθόδους, μπορεί να γίνει ένα από τα πιο ισχυρά εργαλεία στην ιστορία της μαθηματικής επιστήμης.
Πληροφορίες: Thomas Hubert et al, Olympiad-level formal mathematical reasoning with reinforcement learning, Nature (2025). DOI: 10.1038/s41586-025-09833-y
Πηγή: Nature





